This is the third in a series of 4 posts about the selective use of cursor sharing in scheduled processes in PeopleSoft.
- Introduction
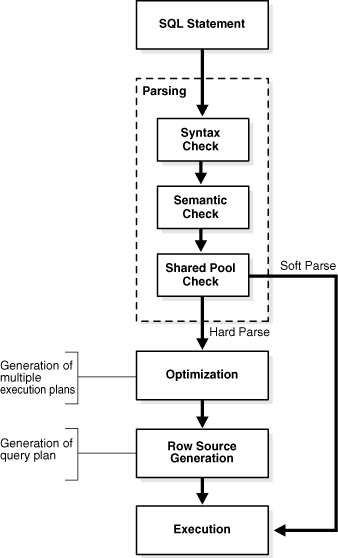
- What happens during SQL Parse? What is a 'hard' parse? What is a 'soft' parse? The additional overhead of a hard parse.
- How to set CURSOR_SHARING for specific scheduled processes
- How to identify candidate processes for cursor sharing.
Cursor Sharing
If you cannot remove the literal values in the application SQL code, then another option is to enable cursor sharing and have Oracle do it. Literals are converted to bind variables before the SQL is parsed; thus, statements that only differ in the literal values can be treated as the same statement. If the statement is still in the shared pool, it is not fully reparsed and uses the same execution plan.
Oracle cautions against using cursor sharing as a long-term fix: "The best practice is to write sharable SQL and use the default of EXACT for CURSOR_SHARING… FORCE is not meant to be a permanent development solution."
I realise that I am now about to suggest doing exactly that, but only for specific processes, and never for the whole database. Over the years, I have tested enabling cursor sharing at database level a few times and have never had a good experience.
However, enabling cursor sharing in a few carefully selected processes can be beneficial. It can save some of the time spent in the database on hard parse, but will have no effect on the time that PeopleSoft processes spend generating the SQL.
Session Settings for Processes Executed on the Process Scheduler
- see Setting Oracle Session Parameters for Specific Process Scheduler Processes
- The scripts are available on GitHub
- Trigger: set_prcs_sess_parm_trg.sql. The trigger expects that psftapi.sql has also been installed.
- Example metadata set_prcs_sess_parm.sql
CREATE OR REPLACE TRIGGER sysadm.set_prcs_sess_parm
BEFORE UPDATE OF runstatus ON sysadm.psprcsrqst
FOR EACH ROW
FOLLOWS sysadm.psftapi_store_prcsinstance
WHEN (new.runstatus = 7 AND old.runstatus != 7 AND new.prcstype != 'PSJob')
DECLARE
l_cmd VARCHAR2(100 CHAR);
…
BEGIN
FOR i IN (
WITH x as (
SELECT p.*
, row_number() over (partition by param_name
order by NULLIF(prcstype, ' ') nulls last, NULLIF(prcsname, ' ') nulls last,
NULLIF(oprid , ' ') nulls last, NULLIF(runcntlid,' ') nulls last) priority
FROM sysadm.PS_PRCS_SESS_PARM p
WHERE (p.prcstype = :new.prcstype OR p.prcstype = ' ')
AND (p.prcsname = :new.prcsname OR p.prcsname = ' ')
AND (p.oprid = :new.oprid OR p.oprid = ' ')
AND (p.runcntlid = :new.runcntlid OR p.runcntlid = ' '))
SELECT * FROM x WHERE priority = 1
) LOOP
…
IF NULLIF(i.parmvalue,' ') IS NOT NULL THEN
l_cmd := 'ALTER SESSION '||i.keyword||' '||l_delim||i.param_name||l_delim||l_op||i.parmvalue;
EXECUTE IMMEDIATE l_cmd;
END IF;
END LOOP;
EXCEPTION
WHEN OTHERS THEN …
END;
/
INSERT INTO sysadm.ps_prcs_sess_parm (prcstype, prcsname, oprid, runcntlid, keyword, param_name, parmvalue)
with x as (
select 'inmemory_query' param_name, 'SET' keyword, 'DISABLE' parmvalue from dual --Disable inmemory
union all select 'cursor_sharing' , 'SET' keyword, 'FORCE' from dual --to mitigate excessive parse
), y as (
select prcstype, prcsname, ' ' oprid, ' ' runcntlid
from ps_prcsdefn
where prcsname IN('GLPOCONS')
)
select y.prcstype, y.prcsname, y.oprid, y.runcntlid, x.keyword, x.param_name, x.parmvalue
from x,y
/
Stand-alone Application Engine (PSAE) -v- Application Engine Server PSAESRV
Cursor Sharing Application Engine Programs Spawned Directly by COBOL Programs
- See gfc_jrnl_ln_gl_jedit2_trigger.sql
- This update is specific to this process, so the trigger is simply hard-coded. It does not use any metadata.
- The after row part of the trigger copies the process instance number from the JRNL_LN rows being inserted into a local variable. This is deliberately minimal so that overhead on the insert is minimal
- The after statement part of the trigger cannot be directly read from the table that was updated. Instead, it checks that the process instance number, that was captured during the after row section and stored in the local variable, is for an instance of FSPCCURR or GLPOCONS that is currently processing (PSPRCSRQST.RUNSTATUS = '7'). If so it sets CURSOR_SHARING to FORCE at session level.
- The ALTER SESSION command is Data Dictionary Language (DDL). In PL/SQL this must be executed as dynamic code.
- The FSPCCURR and GLPOCONS COBOL processes may each spawn GL_JEDIT2 many times. Each runs as a separate stand-alone PSAE process that makes a new connection to the database, runs and then disconnects. Cursor sharing is enabled separately for each.
REM gfc_jrnl_ln_gl_jedit2_trigger.sql
CREATE OR REPLACE TRIGGER gfc_jrnl_ln_gl_jedit2
FOR UPDATE OF process_instance ON ps_jrnl_ln
WHEN (new.process_instance != 0 and old.process_instance = 0)
COMPOUND TRIGGER
l_process_instance INTEGER;
l_runcntlid VARCHAR2(30);
l_module VARCHAR2(64);
l_action VARCHAR2(64);
l_prcsname VARCHAR2(12);
l_cursor_sharing CONSTANT VARCHAR2(64) := 'ALTER SESSION SET cursor_sharing=FORCE';
AFTER EACH ROW IS
BEGIN
l_process_instance := :new.process_instance;
END AFTER EACH ROW;
AFTER STATEMENT IS
BEGIN
IF l_process_instance != 0 THEN
dbms_application_info.read_module(l_module,l_action);
IF l_module like 'PSAE.GL_JEDIT2.%' THEN --check this session is instrumented as being GL_JEDIT2
--check process instance being set is a running FSPCCURR process
SELECT prcsname, runcntlid
INTO l_prcsname, l_runcntlid
FROM psprcsrqst
WHERE prcsinstance = l_process_instance
AND prcsname IN('FSPCCURR','GLPOCONS')
AND runstatus = '7';
l_module := regexp_substr(l_module,'PSAE\.GL_JEDIT2\.[0-9]+',1,1)
||':'||l_prcsname||':PI='||l_process_instance||':'||l_runcntlid;
dbms_application_info.set_module(l_module,l_action);
EXECUTE IMMEDIATE l_cursor_sharing;
END IF;
END IF;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL; --cannot find running fspccurr/glpocons with this process instance number
WHEN OTHERS THEN
NULL;
END AFTER STATEMENT;
END gfc_jrnl_ln_gl_jedit2;
/


 @go-faster.co.uk on BlueSky
@go-faster.co.uk on BlueSky


