This is the second in a series of 4 posts about the selective use of cursor sharing in scheduled processes in PeopleSoft.
- Introduction
- What happens during SQL Parse? What is a 'hard' parse? What is a 'soft' parse? The additional overhead of a hard parse.
- How to set CURSOR_SHARING for specific scheduled processes.
- How to identify candidate processes for cursor sharing.
To understand why cursor sharing can be beneficial it is
necessary to understand
- What happens when Oracle parses and executes a SQL statement?.
- How some PeopleSoft processes dynamically construct SQL statements
SQL Processing: 'Hard' Parse -v- 'Soft' Parse
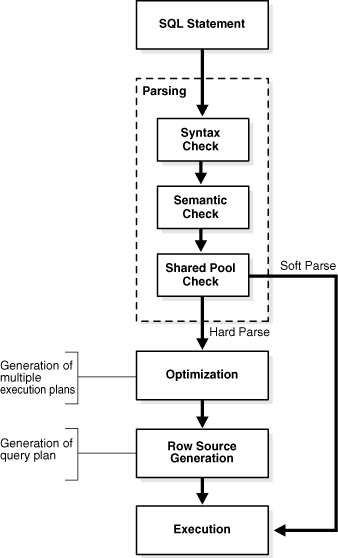
- Syntax Check: Is the statement syntactically valid?
- Semantic Check: Is the statement meaningful? Do the referenced objects exist and is the user allowed to access them?
- SGA Check: Does the statement already exist in the shared SQL area?
- Generation of the optimal execution plan
- Row Source Generation - The execution plan is used to generate an iterative execution plan that is usable by the rest of the database.
What is Cursor Sharing?
The database allows only textually identical statements to share a cursor. By default, the CURSOR_SHARING parameter is set to EXACT, and thus is disabled. "The optimizer generates a plan for each statement based on the literal value."
When CURSOR_SHARING is set to FORCE, the database replaces literal values with system-generated variables. The database still only exactly matches statements, but after the literal values have been substituted, thus giving the appearance of matching statements that differ only by their literal values. "For statements that are identical after bind variables replace the literals, the optimizer uses the same plan. Using this technique, the database can sometimes reduce the number of parent cursors in the shared SQL area." The database only performs a soft parse.
In systems, such as PeopleSoft, that generate many distinct statements, cursor sharing can significantly reduce hard parse, and therefore CPU and time spent on it.
Sources of Hard Parse in PeopleSoft
- In Application Engine, %BIND() resolves to a literal value rather than bind variable in the resulting SQL statement unless the ReUseStatement attribute is enabled. The problem is that it is disabled by default, and there are limitations to when it can be set.
- Dynamic statements in COBOL processes. This is effectively the same behaviour as Application Engine, but here the dynamic generation of SQL is hard-coded in the COBOL from a combination of static fragments and configuration data. PeopleSoft COBOL programs generally just embed literal values in such statements because it is easier than creating dynamic SQL statements with possibly varying numbers of bind variables.
- In nVision where 'dynamic selectors' and 'use literal values' tree performance options are selected. These settings are often preferable because the resulting SQL statements can make effective use of Bloom filters and Hybrid Column Compression (on Exadata). The penalty is that it can lead to more hard parse operations.
ReUseStatement -v- Cursor Sharing
- ReUseStatement cannot be introduced across the board, but only on steps that meet certain criteria set out in the documentation. It doesn't work when dynamic code is generated with %BIND(…,NOQUOTES), or if a %BIND() is used in a SELECT clause. Worse, setting this attribute incorrectly can cause the application to function incorrectly. So each change has to be tested carefully.
- When a customer sets the ReUseStatement attribute in the delivered code, it is a customisation to an Application Engine step that has to be migrated using Application Designer. It then has to be maintained to ensure that subsequent PeopleSoft releases and patches do not revert it.
- There is no equivalent option for PeopleSoft COBOL, SQR, or nVision. The way that SQL is generated in each is effectively hard-coded.
Recommendation: It is not a case of either ReUseStatement or Cursor Sharing. It may be both. If you are writing your own Application Engine code, or customising delivered code anyway, then it is usually advantageous to set ReUseStatement where you can. You will save non-database execution time as well as database time because you are then using bind variables, and Application Engine does not have to spend time generating the text of a new SQL statement with new literal values for every execution. You may still benefit from cursor sharing for statements where you cannot set ReUseStatement.
However, as you will see in the last article in this series, cursor sharing is not always effective, you have to test.


 @go-faster.co.uk on BlueSky
@go-faster.co.uk on BlueSky



No comments :
Post a Comment