Recently, I wrote about the
lookup exclusion table, and then I started to think about identifying automatic lookups that should suppressed. The following query will identify all the records that are used as look-up records.
SELECT DISTINCT r.recname
FROM pspnlfield p
, psrecfielddb f
, psrecdefn r
WHERE p.fieldname = f.fieldname
AND p.recname = f.recname
AND r.recname = f.edittable
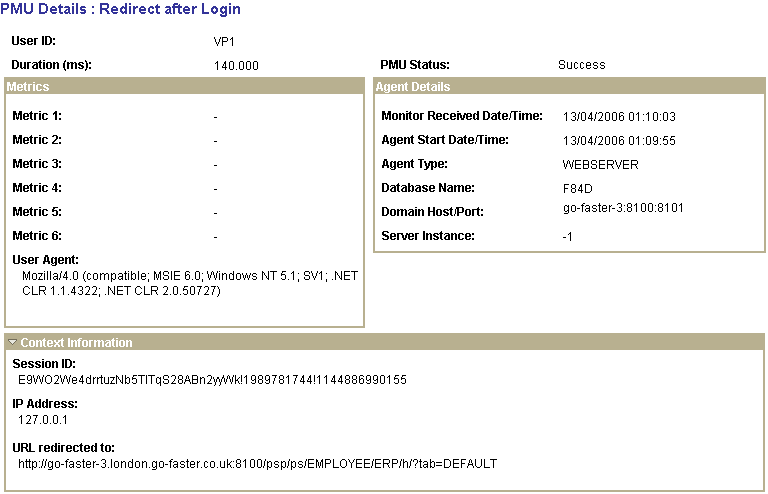
I started on the basis that this is a performance issue. I took a minimalist approach that I would only suppress lookups that were consuming a significant amount of tine. So I looked at whether it was possible to use performance Monitor data to identify long running lookups. When you capture a PMU either through sampling or a performance trace you get a heirarchy of the following transactions when you performance a lookup.
- 401:Entry and exit for Component search and processing on AppSrv
- 403:Modal component/secondary page/lookup page from a Level 1
- 408:All SQL calls excluding PMUs 406 and 407
Note: Transaction 408 is only collected if you have verbose trace enabled for PSAPPSRV. Be aware that this level of tracing can have an impact on performance.Performance monitor transactions are held in the table
PSPMTRANSHIST. This table can become rather large, I found it easier to extract the transaction types that are of interest to me into another table, and then analyse that data.
DROP TABLE dmktranshist;
CREATE TABLE dmktranshist PCTFREE 0 as
SELECT pm_trans_defn_id
, pm_instance_id, pm_parent_inst_id, pm_top_inst_id
, pm_context_value1, pm_context_value2, pm_context_value3
, pm_metric_value7
--, pm_addtnl_descr
, pm_trans_duration
FROM pspmtranshist
WHERE pm_trans_defn_set = 1
AND pm_trans_defn_id IN(401,403,408)
AND ( pm_trans_defn_id = 401
OR (pm_trans_defn_id = 403 AND pm_context_value3 = 'Launch Look up Page')
OR (pm_trans_defn_id = 408 AND pm_metric_value7 LIKE 'SELECT PS%' AND SUBSTR(pm_metric_value7,10,1) = '_')
);
CREATE UNIQUE INDEX dmktranshist1
ON dmktranshist(pm_instance_id) PCTFREE 0;
CREATE INDEX dmktranshist2
ON dmktranshist(pm_trans_defn_id, pm_parent_inst_id, pm_metric_value7)
PCTFREE 0 COMPRESS 1;
CREATE INDEX dmktranshist3
ON dmktranshist(pm_trans_defn_id, pm_context_value3)
PCTFREE 0 COMPRESS 1;
ANALYZE TABLE dmktranshist ESTIMATE STATISTICS FOR ALL COLUMNS;
I have constructed two queries to identify component look-ups that are acocunting for a large amount of response time. This first query simply sums the duration and counts the number of executions of each lookup record. Details of the component and page are also available on the table.
COLUMN pm_instance_id FORMAT 999999999999999
COLUMN pm_parent_inst_id FORMAT 999999999999999
COLUMN pm_top_inst_id FORMAT 999999999999999
COLUMN component FORMAT a25 HEADING 'Component'
COLUMN page FORMAT a35 HEADING 'Page'
COLUMN pm_context_value3 HEADING 'Context'
ttitle 'Total Time grouped by Lookup Record'
SELECT
-- a.pm_context_value1 component,
-- a.pm_context_value2 page,
a.pm_context_value3
, SUM(b.pm_trans_duration)/1000 duration
, COUNT(*) num_lookups
, SUM(b.pm_trans_duration)/1000/COUNT(*) avg_duration
FROM dmktranshist a
, dmktranshist b
WHERE a.pm_trans_defn_id = 401
AND b.pm_trans_defn_id = 403
AND a.pm_top_inst_id = b.pm_top_inst_id
AND a.pm_instance_id = b.pm_parent_inst_id
AND b.pm_context_value3 = 'Launch Look up Page'
GROUP BY a.pm_context_value3 --,a.pm_context_value1 ,a.pm_context_value2
--HAVING SUM(b.pm_trans_duration)>=50000 /*use this restrict runs to top lookups.*/
ORDER BY 2 DESC
/
Total Time grouped by Lookup Record
Context
--------------------------------------------------------------------
DURATION NUM_LOOKUPS AVG_DURATION
---------- ----------- ------------
Click Prompt Button/Hyperlink for Field DEPOSIT_CONTROL.BANK_CD
.849 1 .849
Click Prompt Button/Hyperlink for Field DEPOSIT_CONTROL.BANK_ACCT_KEY
.319 1 .319
...
The other query additionally retrieves the SQL that was run, but this data is only available if the PMU trace was at Verbose level on the PSAPPSRV process.
ttitle 'SQL run by lookup - only with verbose or debug level tracing'
SELECT a.pm_context_value1 component
, a.pm_context_value2 page
, a.pm_context_value3
, c.pm_metric_value7
, b.pm_trans_duration/1000 duration
FROM dmktranshist a, dmktranshist b, dmktranshist c
WHERE a.pm_trans_defn_id = 401
AND b.pm_trans_defn_id = 403
AND c.pm_trans_defn_id = 408
AND a.pm_top_inst_id = b.pm_top_inst_id
AND b.pm_top_inst_id = c.pm_top_inst_id
AND c.pm_top_inst_id = a.pm_top_inst_id
AND a.pm_instance_id = b.pm_parent_inst_id
AND b.pm_instance_id = c.pm_parent_inst_id
AND b.pm_context_value3 = 'Launch Look up Page'
AND c.pm_metric_value7 LIKE 'SELECT PS%'
AND SUBSTR(c.pm_metric_value7,10,1) = '_'
AND c.pm_instance_id = (
SELECT MAX(c1.pm_instance_id)
FROM dmktranshist c1
WHERE c1.pm_parent_inst_id = c.pm_parent_inst_id
AND c1.pm_top_inst_id = c.pm_top_inst_id
AND c1.pm_metric_value7 LIKE 'SELECT PS%'
AND c1.pm_trans_defn_id = 408
AND SUBSTR(c1.pm_metric_value7,10,1) = '_')
/
Component Page
------------------------- -----------------------------------
Context
--------------------------------------------------------------------
PM_METRIC_VALUE7
--------------------------------------------------------------------
DURATION
----------
PAYMENT_EXPRESS.GBL PAYMENT_EXPRESS1
Click Prompt Button/Hyperlink for Field DEPOSIT_CONTROL.BANK_CD
SELECT PS_BANK_AR_BD_VW A
.849
PAYMENT_EXPRESS.GBL PAYMENT_EXPRESS1
Click Prompt Button/Hyperlink for Field DEPOSIT_CONTROL.BANK_ACCT_KEY
SELECT PS_BANK_AR_D_VW A
.319
Suppressing the automatic lookup saves the user from waiting for an unnecessary query. The question is what is the criteria for adding a record to the lookup exclusion table.
- Certainly if a lookup record returns more than 300 rows it should not be executed automatically, because only the first 300 rows will be returned, and then the user will probably not have the row they are looking for and they will have to add search criteria and repeat the search.
- There is a good case for suppressing the automatic lookup when it returns more than 100 rows. The results will return up to 3 pages of 100 rows per page. Then the user may well have to navigate to a different page in order to find what they are looking for.
- Having discussed this issue with a few people, there is some support for the suggestion that the automatic search should be supressed for records with more than 25-50 rows. If there are more rows than this, the user is likely to have to scroll down the page the desired row.
The number of rows that a lookup record may retrieve is therefore a good criteria for deciding whether to suppress the automatic lookup. So I have constructed the following SQL script to identify all candidate records and count the number of rows that each returns. First I need a table in which to store the results.
CREATE TABLE lux_cand
(recname VARCHAR2(15) NOT NULL
,sqltablename VARCHAR2(18)
,rectype NUMBER NOT NULL
,num_lookups NUMBER NOT NULL
,num_rows NUMBER
,lead_key VARCHAR2(18)
,num_lead_keys NUMBER
,lastupddttm DATE )
/
CREATE UNIQUE INDEX lux_cand ON lux_cand(recname)
/
Then all the records with lookup exclusion fields will be copied into our new working storage table.
INSERT INTO lux_cand (recname, sqltablename, rectype, lead_key, num_lookups)
SELECT r.recname
, CASE WHEN r.rectype IN(0,1,6) THEN /*regular records*/
DECODE(r.sqltablename,' ','PS_'r.recname,r.sqltablename)
END
, r.rectype
, k.fieldname
, count(*) num_lookups
FROM pspnlfield p
, psrecfielddb f
, psrecdefn r
LEFT OUTER JOIN pskeydefn k
ON k.recname = r.recname
AND k.indexid = '_'
AND k.keyposn = 1
WHERE p.fieldname = f.fieldname
AND p.recname = f.recname
AND f.edittable > ' '
AND r.recname = f.edittable
GROUP BY r.recname, r.rectype, k.fieldname
, DECODE(r.sqltablename,' ','PS_'r.recname,r.sqltablename)
/
COMMIT
/
/*if SETID is a key, the we will group by SETID*/
UPDATE lux_cand l
SET l.lead_key = 'SETID'
WHERE l.lead_key IS NULL
AND EXISTS(
SELECT 'x'
FROM psrecfielddb k
WHERE k.recname = l.recname
AND k.fieldname = 'SETID'
AND MOD(k.useedit,2) = 1 /*bit 1 of useedit is set to one for key columns*/
);
/*store first defined key column*/
UPDATE lux_cand l
SET l.lead_key = (
SELECT k.fieldname
FROM psrecfielddb k
WHERE k.recname = l.recname
AND MOD(k.useedit,2) = 1
AND k.fieldnum = (
SELECT MIN(k1.fieldnum)
FROM psrecfielddb k1
WHERE k1.recname = k.recname
AND MOD(k1.useedit,2) = 1 ))
WHERE l.lead_key IS NULL
;
/*clear sqltablename where table does not exist*/
UPDATE lux_cand l
SET l.sqltablename = ''
WHERE l.sqltablename IS NOT NULL
AND l.rectype = 0
AND NOT EXISTS(
SELECT 'x'
FROM user_tables o
WHERE o.table_name = l.sqltablename) ;
/*clear sqltablename where the view does not exist*/
UPDATE lux_cand l
SET l.sqltablename = ''
WHERE l.sqltablename IS NOT NULL
AND l.rectype IN(1,6)
AND NOT EXISTS(
SELECT 'x'
FROM user_views o
WHERE o.view_name = l.sqltablename)
/
/*deliberately exclude this view from the test, it takes a long time to count the rows and it should be on the lookup exclusion table regardless*/
UPDATE lux_cand l
SET l.lastupddttm = SYSDATE, l.num_rows = 301
WHERE l.recname IN('PSFIELDRECDVW')
AND l.lastupddttm IS NULL
/
COMMIT
/
/*count number of rows in each table*/
DECLARE
l_num_rows INTEGER;
l_lead_keys INTEGER;
BEGIN
FOR l IN (
SELECT l.* FROM lux_cand l
WHERE l.lastupddttm IS NULL
AND l.sqltablename IS NOT NULL
ORDER BY SIGN(l.rectype) /*do tables first*/
, case when 'PS_'l.recname = l.sqltablename then 0 else 1 end /*tools tables last*/
, l.rectype /*order by rectype*/
, l.recname
) LOOP
l_num_rows := 0;
l_lead_keys := 0;
IF l.lead_key = 'SETID' THEN /*count max rows per setid*/
EXECUTE IMMEDIATE 'SELECT MAX(num_rows), COUNT(*) FROM (SELECT COUNT(*) num_rows FROM 'l.sqltablename' GROUP BY 'l.lead_key')' INTO l_num_rows, l_lead_keys;
UPDATE lux_cand
SET num_rows = NVL(l_num_rows,0)
, num_lead_keys = NVL(l_lead_keys,0)
, lastupddttm = SYSDATE
WHERE recname = l.recname;
ELSE /*count number of rows*/
EXECUTE IMMEDIATE 'SELECT COUNT(*) FROM 'l.sqltablename' WHERE rownum <= 301' INTO l_num_rows; UPDATE lux_cand SET num_rows = NVL(l_num_rows,0) , lastupddttm = SYSDATE WHERE recname = l.recname;
END IF;
COMMIT;
END LOOP;
END;
/
Now, the table
LUX_CAND contains a list of all the tables and view used as lookups, and the number of rows that they return (I cannot do anything about PeopleSoft dynamic views). The next thing is to add any record that returns too many rows into the lookup exclusion table.
/*put records with too many rows into the exclusion table*/
INSERT INTO psrecxl
SELECT recname FROM lux_cand WHERE num_rows > 100
MINUS
SELECT recname FROM psrecxl
/
Don't worry about an negative effects of having a large number records in the lookup exclusion table. This information is cached by the application server. Although there is no version number on
PSRECXL, when you save an update to the lookup exclusion table, there is component PeopleCode that updates the SYS and PPC version numbers, which causes the application server to recache this table, so that changes take effect immediately. So when updating
PSRECXL with this script, it is also necessary to increment the version numbers.
UPDATE PSVERSION SET VERSION = VERSION + 1 WHERE OBJECTTYPENAME IN('SYS','PPC');
UPDATE PSLOCK SET VERSION = VERSION + 1 WHERE OBJECTTYPENAME IN('SYS','PPC');
COMMIT;On my Financials 8.4 demo system I found 4089 records being used as lookup records. Of those 557 have over 300 rows, 1058 have over 100 rows, and 1711 records return over 25 rows.
On balance, I think that I would be prepared to add all 1711 records to the lookup exclusion table. It would save unecessary searches.










 @go-faster.co.uk on BlueSky
@go-faster.co.uk on BlueSky



{kind=link}