This is part of a series of articles about new features and differences in PeopleTools 8.54 that will be of interest to the Oracle DBA.
Partitioning in Oracle
Partitioning of table (and index) segments involves breaking them into several smaller segments where certain data values only occur in certain segments. Thus if a query is looking for a certain data value it may be able to eliminate some partitions without having to scan them because by definition those values cannot occur in those partitions. Thus saving logical and physical read, and improving performance. This is called partition elimination or pruning. It is often the principal reason for partitioning a table.Physically each partition in a partitioned table is a table, but logically the partitions form a single table. There should be no need to change application code in order to use partitioning, but the way the code is written will affect Oracle's ability to perform partition elimination.
The following diagram is taken from the Oracle 11g Database VLDB and Partitioning Guide

If a query was only looking data in March, then it could eliminate the January and February partitions without inspecting them. However, if it was filtering data by another column then it would still have to inspect all three partitions. Application design will determine whether, and if so how to partition a table.
NB: I can't mention partitioning without also saying that Partitioning Option is a licensed feature of Oracle Database Enterprise Edition.
Partitioning in PeopleTools prior to 8.54
I have to declare an interest. I have been using partitioning in PeopleSoft since PeopleTools 7.5 when it was introduced in Oracle 8i. The line from PeopleSoft was that you can introduce partitioning without invalidating your support (the same is not true of E-Business suite). Application Designer won't generate partition DDL, so you were supposed to give your DDL scripts to the DBA who would add the partition clauses. So you if wanted to use partitioning, you would be plunged into a hellish world of manual scripting. One of the key benefits of Application Designer is that it generates the DDL for you.Since 2001, I have developed a PL/SQL utility that effectively reverse engineers the functionality of Application Designer that builds DDL scripts, but then adds the partitioning clauses. It also adds partitions, and has been extended to assist with partition-wise data archive/purge. It is in uses at a number sites using Global Payroll (for which it was originally designed) and Financials (see Managing Oracle Table Partitioning in PeopleSoft Applications with GFC_PSPART Package)
So in investigating the new partitioning feature of PeopleTools 8.54 I was concerned:
- Is my partitioning utility was now obsolete? Or should I continue to use it?
- How would I be able to retrofit existing partitioning into PeopleTools?
Partitioning in PeopleTools 8.54
I am going to illustrate the behaviour of the new partition support with a number of example.Example 1: Range Partitioning PSWORKLIST
In this example, I will range partition table PSWORKLIST on the INSTSTATUS column. The valid statuses for this column are:| INSTSTATUS | Description |
|---|---|
| 0 | Available |
| 1 | Selected |
| 2 | Worked |
| 3 | Cancelled |
- the first partition will only contain statuses 0 and 1, which are the open worklist items,
- the other partition will contain the other statuses; 2 and 3 which are the closed items.
This is something that I have actually done on a customer site, and it produced a considerable performance improvement.
PeopleSoft provides a component that allows you to configure the partitioning strategy for a record. However, I immediately ran into my first problem.
- The Partitioning Utility component will only permit me to partition by a PeopleSoft unique key column. If a query doesn't have a predicate on the partitioning column, then Oracle will certainly not be able to prune any partitions, and the query will perform no better than if the table had not been partitioned. While a column frequently used in selective criteria is often the subject of an index, and sometimes the unique key, this is not always the case. It does not make sense to assume this in this utility component.
- In this case, INSTSTATUS is not part of any delivered index, though I added it to index B. I have seen that the application frequently queries the PSWORKLIST table by INSTSTATUS, so it does make sense to partition it on that column.

SELECT A.RECNAME
,A.FIELDNAME
FROM PSRECFIELDALL A
WHERE %DecMult(%Round(%DECDIV(A.USEEDIT,2),0 ) , 2) <> A.USEEDIT
DROP TABLE PS_ST_RM2_TAO
/
SELECT A.RECNAME
,A.FIELDNAME
FROM PSRECFIELDALL A /* WHERE %DecMult(%Round(%DECDIV(A.USEEDIT,2),0 ) , 2) <> A.USEEDIT*/
, PSDBFIELD B
WHERE A.FIELDNAME = B.FIELDNAME
AND B.FIELDTYPE IN(0,2,3,4,5,6)

- The component automatically adds a MAXVALUE partition. This means that is valid to put any value into the partition column, otherwise it can cause an error. However, it might not be what I want.
- The component also adds a table storage clause, overriding anything specified in the record, with a fixed PCTFREE 20 which applies to all partitions. Again this might not be what I want. The value of PCTFREE depends on whether and how I update data in the table.
- There are a number of things that I can't control in this component
- The name of MAXVALUE partition
- The tablespace of the MAXVALUE partition, which defaults to be the same tablespace as the last defined partition, which might not be what I want.
- Any other physical attribute of any of the partitions, for example I might want a different PCTFREE on partitions containing data will not be updated.
- The component adds clause to enable row movement. This permits Oracle to move rows between partitions if necessary when the value of the partitioning key column is updated. In this case it is essential because as worklist items are completed they move from the first partition to the other. ALTER TABLE ... SHRINK requires row moment, so it is useful to enable it generally.

The create table script (PSBUILD.SQL) does not contain any partition DDL. So first you build the table and then alter it partitioned. To be fair, this limitation is set out in the PeopleTools documentation, and it is not unreasonable as you would often build the table and then decide to partition it. I do the same in my own utility.
-- Start the Transaction
-- Create temporary table
CREATE TABLE PSYPSWORKLIST (BUSPROCNAME VARCHAR2(30) DEFAULT ' ' NOT
NULL,
…
DESCR254_MIXED VARCHAR2(254) DEFAULT ' ' NOT NULL) PARTITION BY
RANGE (INSTSTATUS)
(
PARTITION OPEN VALUES LESS THAN (2) TABLESPACE PTTBL,
PARTITION PE_MAXVALUE VALUES LESS THAN (MAXVALUE) TABLESPACE PTTBL
)
PCTFREE 20 ENABLE ROW MOVEMENT
/
-- Copy from source to temp table
INSERT INTO PSYPSWORKLIST (
BUSPROCNAME,
…
DESCR254_MIXED)
SELECT
BUSPROCNAME,
…
DESCR254_MIXED
FROM PSWORKLIST
/
-- CAUTION: Drop Original Table
DROP TABLE PSWORKLIST
/
-- Rename Table
RENAME PSYPSWORKLIST TO PSWORKLIST
/
-- Done
CREATE UNIQUE INDEX PS_PSWORKLIST ON PSWORKLIST (BUSPROCNAME,
ACTIVITYNAME,
EVENTNAME,
WORKLISTNAME,
INSTANCEID)
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 40960 NEXT 106496 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSINDEX"
/
ALTER INDEX PS_PSWORKLIST NOPARALLEL LOGGING
/
…
CREATE INDEX PSBPSWORKLIST ON PSWORKLIST (OPRID,
INSTSTATUS)
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 40960 NEXT 106496 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSINDEX"
/
ALTER INDEX PSBPSWORKLIST NOPARALLEL LOGGING
/
CREATE INDEX PSBWORKLIST ON PSWORKLIST
('') LOCAL TABLESPACE PTTBL
/The DDL to create partitioned index does not seem to appear properly. The first CREATE INDEX command was generated by Application Designer extracting it from the catalogue with DBMS_METADATA. This functionality was introduced in PeopleTools 8.51 to preserve existing configuration.The second create index comes from the partitioning definition.
- The index column list is missing, it should come from the column list is defined in Application Designer.
- The locally partitioned index is the same tablespace as the table instead of the tablespace defined on the index.
- I would not normally keep indexes in the same tablespace as the table (the rationale is that in the case of having to recover only a tablespace with indexes then I could rebuild it instead of recovering it).
- I strongly recommend against generally allowing parallel query in all SQLs that reference a partitioned table in an OLTP system, which is what PeopleSoft is. There are occasions where parallel query is the right thing to do, and in those cases I would use a hint, or SQL profile or SQL patch.

If you trace the SQL generated by this component while entering partition details and generating partition DDL, then the only two tables that are updated at all; PS_PTTBLPARTDDL and PS_PTIDXPARTDDL. They are both keyed on RECNAME and PLATFORMID and have just one other column, a CLOB to hold the DDL.
- The partition information disappears because there is nowhere to hold it persistently, and the component cannot extract it from the DDL. It was being entered into a derived work record.
- So it is not going to be much help when I want to adjust partitioning in a table that is already partitioned. For example, over time, I might want to add new partitions, compress static partitions, or purge old ones.
- It is also clear that there is no intention to support different partitioning strategies for different indexes on the same table. There are certainly cases where a table will one or more locally partitioned indexes and some global indexes that may or may not be partitioned.
- Even these two tables are not fully integrated into Application Designer. There is a throwaway line in Appendix E of the Data Management Guide - Administering Databases on Oracle:"Record and index partitioning is not migrated as part of the IDE project. If you want to migrate the partitioning metadata along with the record, you will need to…" copy it yourself and it goes on to recommend creating a Data Migration Project in the Data Migration Workbench"
Sample 2: Import Existing Partitioning
Sticking with PSWORKLIST, I have partitioned it exactly the way I want.CREATE TABLE sysadm.psworklist
(busprocname VARCHAR2(30) NOT NULL
…
,descr254_mixed VARCHAR2(254) NOT NULL
)
TABLESPACE PTTBL
PCTFREE 10 PCTUSED 80
PARTITION BY RANGE(INSTSTATUS)
(PARTITION psworklist_select_open VALUES LESS THAN ('2')
,PARTITION psworklist_worked_canc VALUES LESS THAN (MAXVALUE) PCTFREE 1 PCTUSED 90
)
ENABLE ROW MOVEMENT
PARALLEL
NOLOGGING
/
…
ALTER TABLE sysadm.psworklist LOGGING NOPARALLEL MONITORING
/
…
CREATE INDEX sysadm.ps0psworklist ON sysadm.psworklist
(transactionid
,busprocname
,activityname
,eventname
,worklistname
,instanceid
)
TABLESPACE PSINDEX
PCTFREE 10
PARALLEL
NOLOGGING
/
…
CREATE INDEX sysadm.psbpsworklist ON sysadm.psworklist
(oprid
,inststatus
)
LOCAL
(PARTITION psworklistbselect_open
,PARTITION psworklistbworked_canc PCTFREE 1
)
TABLESPACE PSINDEX
PCTFREE 10
PARALLEL
NOLOGGING
/
ALTER INDEX sysadm.psbpsworklist LOGGING
/
ALTER INDEX sysadm.psbpsworklist NOPARALLEL
/
The DDL in the Maintain Partitioning box in Application Designer is extracted from the data dictionary using the Oracle supplied DBMS_METADATA package. Application Designer has done this since PeopleTools 8.51 for index build scripts, but now you can see the DDL directly in the tool.
 When I generate an alter table script I still get two create index command for the partitioned index. The second one comes from the generated partition DDL and is not correct because it still doesn't have a column list.
When I generate an alter table script I still get two create index command for the partitioned index. The second one comes from the generated partition DDL and is not correct because it still doesn't have a column list.CREATE INDEX PSBPSWORKLIST ON PSWORKLIST (OPRID,
INSTSTATUS)
PCTFREE 10 INITRANS 2 MAXTRANS 255 LOGGING
STORAGE(
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSINDEX" LOCAL
(PARTITION "PSWORKLISTBSELECT_OPEN"
PCTFREE 10 INITRANS 2 MAXTRANS 255 LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS
2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSINDEX" ,
PARTITION "PSWORKLISTBWORKED_CANC"
PCTFREE 1 INITRANS 2 MAXTRANS 255 LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS
2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSINDEX" )
/
ALTER INDEX PSBPSWORKLIST NOPARALLEL LOGGING
/
CREATE INDEX PSBPSWORKLIST ON PSWORKLIST ('') LOCAL TABLESPACE
PTTBL
/Example 3 - GP_RSLT_ACUM
I have now chosen to partition one of the Global Payroll result tables. This is often the largest table in a payroll system. I have seen more than 1 billion rows in this table at one customer. In a Global Payroll system, I usually:- range partition payroll tables on EMPLID to match the streamed processing (in GP streaming means concurrently running several Cobol or Application Engine programs to process different ranges of employees). So there is a 1:1 relationship between payroll processes and physical partitions
- the largest result tables are sub-partitioned on CAL_RUN_ID so each payroll period is in a separate physical partition. Later I can archive historical payroll data by partition.
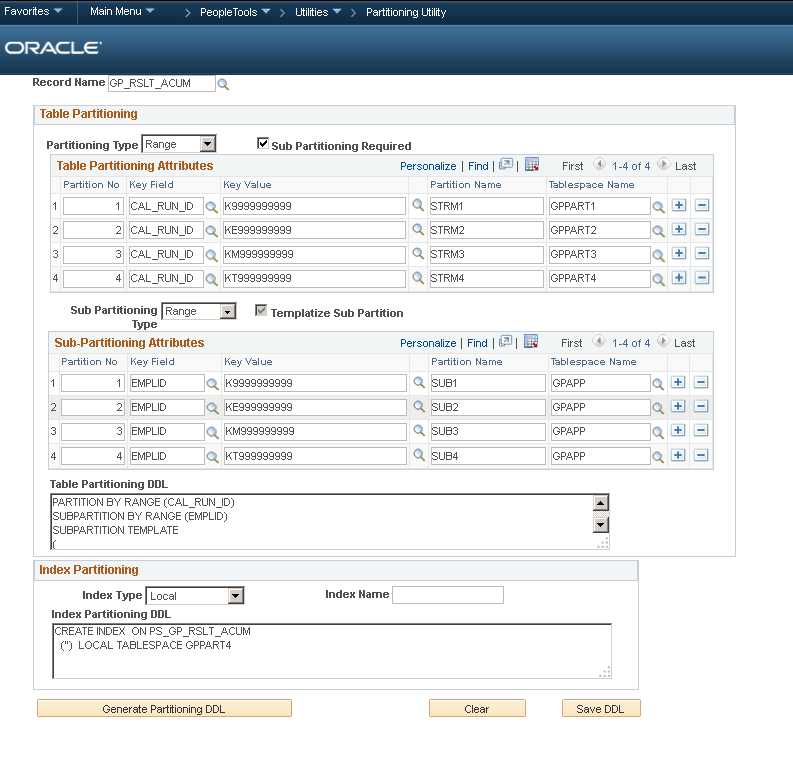
And this is Table DDL that the utility generated.
PARTITION BY RANGE (CAL_RUN_ID)
SUBPARTITION BY RANGE (EMPLID)
SUBPARTITION TEMPLATE
(
SUBPARTITION SUB1 VALUES LESS THAN ('K9999999999'),
SUBPARTITION SUB2 VALUES LESS THAN ('KE999999999'),
SUBPARTITION SUB3 VALUES LESS THAN ('KM999999999'),
SUBPARTITION SUB4 VALUES LESS THAN ('KT999999999') ,
SUBPARTITION PE_MAXVALUE VALUES LESS THAN (MAXVALUE)
)
(
PARTITION STRM1 VALUES LESS THAN ('K9999999999') TABLESPACE GPPART1,
PARTITION STRM2 VALUES LESS THAN ('KE999999999') TABLESPACE GPPART2,
PARTITION STRM3 VALUES LESS THAN ('KM999999999') TABLESPACE GPPART3,
PARTITION STRM4 VALUES LESS THAN ('KT999999999') TABLESPACE GPPART4,
PARTITION PE_MAXVALUE VALUES LESS THAN (MAXVALUE) TABLESPACE GPPART4
)
PCTFREE 20 ENABLE ROW MOVEMENT
- Use of the sub-partition template clause simplifies the SQL. There is certainly a lot less of it. However, it means you get all the sub-partitions within in all partitions. That might not be what you want. In this demo database both employees and calendars are prefixed by something that corresponds to legislature, so some partitions will be empty. They won't take up any physical space, due to deferred segment creation, but it would be better not to build them at all.
- I can specify tablespace on the sub-partitions in the utility component, but there is no tablespace on the sub-partition template in the DDL. I care more about putting different payroll periods into different tablespaces, than different ranges of employees (so I can compress and purge data later) so I swapped the partition key columns and have range partitioned on CAL_RUN_ID and sub-partitioned on EMPLID.
In PeopleTools 8.54, it is not possible to define a single partitioning strategy and consistently apply it to several tables. Even if the data entered into the partition utility component was retained, I would have to enter it again for each table.
Conclusion
When I heard that PeopleTools would have native support for partitioning, if only in Oracle, I was hopeful that we would get something that would bring the process of migrating and building partitioned tables in line with normal tables. Unfortunately, I have to say that I don't think the partitioning support that I have seen so far is particularly useful.- There is no point typing in a lot of partition data into a utility component that doesn't retain the data.
- As with materialized views, table partitioning is something on which DBAs will have to advise and will probably implement and maintain. This component doesn't really help them do anything they already do with a text editor!
- Even the minimal partition data that the utility component does retain is not migrated between environments by Application Designer when you migrate the record.
I would like to see PeopleTools tables to hold partitioning metadata for tables and indexes, and for Application Designer to build DDL scripts to create and alter partitioned tables, to add partitions to existing tables, and then to migrate those definitions between environments.
One positive that I can take from this is that Oracle has now clearly stated that it is reasonable to introduce partitioning into your PeopleSoft application without invalidating your support. The position hasn't actually changed, but now there is clarity.


 @go-faster.co.uk on BlueSky
@go-faster.co.uk on BlueSky



4 comments :
I have a PeopleSoft Finance Application that runs queries.Few large tables have to be partitioned to improve performance on the queries.Those partitioned tables get updated on partition key during regular business operations.Hence i have to keep row movement enabled on the Partitioned table to achieve that.My specific question is ,is there any downside if we keep the row movement enabled permanently on the partitioned table?
Row movement permits operations that might move a row to a different block. Effectively the row is deleted and reinserted, and the overhead is additional redo and undo that that incurs. In practice, there are few things that will happen during normal PeopleSoft operation that will incur this overhead. However, if you don't enable row movement, you won't be able to do certain administrative tasks. Whenever I have partitioned tables in PeopleSoft I have usually enabled row movement.
However, one word of caution. Partitioning ledger tables by FISCAL_YEAR and ACCOUTING_PERIOD is simple and safe. Partitioning other tables needs careful consideration and testing. It depends on the nature of the data and processing, and that varies from customer to customer.
For example, Partitioning by BUSINESS_UNIT and SETID makes good sense in terms of the SQL generated by the application, but you frequently find most of the data in a very few data values. I frequently see JRNL_LN partitioned by JOURNAL_DATE, and I don't think that this always a good idea.
You guessed it right David,I have to partition the PS_JRLN_LN table and PS_VCHR_ACCTG_LINE table by JOURNAL_DATE because my end users have made PSQUERIES in the front end using JOURNAL_DATE.We started having major performance issues for those PSQUERIES and i had to partition both the tables using JOURNAL_DATE.In PS_VCHR_ACCTG_LINE ,JOURNAL_DATE can be a null and hence i had to use Range Partition(Interval Partition does not accept NULLS).Those null values get updated by subsequent business processes and hence i had to enable row movement.I have not been able to talk down the user to use anything apart from JOURNAL_DATE. I would like to know from you why you feel partitioning by JOURNAL_DATE is not a good idea .If front end queries use JOURNAL_DATE as a criteria do i have any other option apart from partitioning on JOURNAL_DATE to better the performance.?
If you are planning to partition several tables, I would suggest you look at Managing Oracle Table Partitioning in PeopleSoft Applications with GFC_PSPART Package (http://www.go-faster.co.uk/gpdoc.htm#Configuring_Operating_Streamed_Payroll). The package is on Github at https://github.com/davidkurtz/gfcbuild.
I don't believe that there is a generic answer to your question. It depends. Please contact me directly to discuss this further.
Post a Comment